
Research
Interpretable decision support model estimation for intracranial aneurysms
Matteo Delucchi, in collaboration with ZHAW
A better understanding of the interplay of intracranial aneurysms (IAs) rupture risk factors can be highly beneficial in making clinical decisions about the treatment of unruptured IAs. IAs are bulges in cerebral arteries present in about 3% of the population. While most of these IAs are asymptomatic, sudden rupture can lead to a type of hemorrhagic stroke, which often has poor functional outcomes. Clinicians base their treatment decisions on a combination of expertise, guidelines, and risk prediction scores. However, weighing treatment risks and benefits remains inherently difficult due to unknown disease mechanisms and interdependent rupture risk factors.
This project aims to create a more accurate and practical clinical decision support system by developing a probabilistic graphical model that accounts for the interdependence among rupture risk factors and incorporates clinical expertise. When it comes to analyzing complex and highly dimensional datasets, additive Bayesian network modelling (R package abn) is a powerful machine-learning approach that can help identify associations. Moreover, it allows for the flexible modelling of continuous and discrete variables of various distribution types and multiple data sources.
We could show, on a single-centre data set, that BNs facilitate knowledge discovery of the IA disease compared to standard statistical analyses. For example, only a few factors are directly associated with IA rupture. To improve the generalisability, we collect a new, multicentre data set of IA rupture risk factors and expand the R package abn to account for more complex data generation processes.

Publication:
A Consistent Hierarchy of Models for Exploratory Experimental Research

Servan Grüninger
Experimental design and analysis necessitates the combination of scientific and mathematical models in a consistent fashion. Every experiment usually begins with a hypothesis about the world, stated in quite general terms and of broad scope: the Primary Model. To inquire about the hypothesis scientifically, it has to be transformed into a hypothesis which is empirically testable with current methods and resources: the Experimental Model. Hence, a suitable experimental context with clearly defined parameters and outcomes must be specified. Both levels are usually stated in the scientific language of the discipline in which the experiment takes place and only the next two levels are in the realm of statistics. First, the data generation process must be described by a Data Model, followed by the specification of the experimental process in the form of the Experimental Design Model which is then combined with a particular Data Analysis Model for analysis. that specifies the statistical measures and tests that are used to analyze the data.
The goal of this thesis is to provide a consistent hierarchical framework relating the inferential paths from a Primary Model about the world to the data gathered and back to the Primary Model in exploratory experiments. The value of such a framework consists in helping expose and prevent logical and mathematical inferential challenges and also aid the consistent and meaningful planning of experiments, which is demonstrated in three use cases.
Novel Machine Learning Algorithms for Large Spatial Data
Tim Gyger, in collaboration with HSLU
The Gaussian Process regression model, provides a flexible method of interpolation by identifying the underlying spatial structure in the data, commonly referred to as Kriging. A recent proposal in advocates the incorporation of tree-boosting algorithms to model the fixed effects in the regression model. This approach has the advantage that complex functions in the predictor variables can be learned. The model parameters are typically estimated through the repetitive calculation of the negative log marginal likelihood and its derivative with respect to the hyperparameters. However, this calculation becomes computationally unfeasible for large datasets.
To address this issue, we propose a novel approach that enables scaling to larger datasets through the utilization of a full-scale covariance approximation (FSA) combined with conjugate gradient algorithms for the linear solves and stochastic trace estimations for the log-determinant and its derivative.
Through first simulations, we evaluated that a simple preconditioner given by the structure of FSA has a highly positive impact on the convergence of the conjugate gradient method and the variance reduction in trace estimations. This leads to improvements in runtime and accuracy of the log-likelihood estimates. Moreover, we investigate a novel approach for a low-rank covariance approximation based on variants of the Lanczos Algorithm. Furthermore, we will apply our model to a real-world dataset describing specific structural characteristics of the Laegeren mountain. We will evaluate the predictive accuracy of our approach and compare it with state-of-the-art methods.
Pruning Sparse Dataframes of Linguistic Data
Marc Lischka, in collaboration with Anna Graff and other NCCR EvolvingLanguage members
With increasing availability of linguistic data in large-scale databases, the perspective of appropriately merging data from such databases via language identifiers (such as glottocodes) and performing large-scale analyses on such aggregated datasets becomes attractive, especially for analyses that aim at testing hypotheses at global scales, for which data collection may not be feasible for large numbers of variables.
Some of these databases have near-complete variable coding density for all languages present (e.g. PHOIBLE, Grambank), others’ variables are coded for very different sets of languages (e.g. AUTOTYP, Lexibank, WALS), resulting in sparse variable-language matrices. Additionally, combining data from various databases results in further sparsity. Our initial dataset including original variables, modified variables and merged variables has an overall coding density of ~15%. It is clear that many languages and variables in such an initial dataset have such low coding densities that including them in analysis is not sufficiently beneficial, e. g. due to their contribution to extra computational time.
We develop an iterative procedure to prune the aggregated matrix, following criteria set with the aim to optimise the language-variable matrix in terms of coding density and taxonomic diversity, primarily. The criteria we employ relate to a) the taxonomic importance of each language given the current language sample (we could call this a “vertical” criterion) and b) weighted density of data for both languages and variables (criterion both “vertical” and “horizontal”). Point (a) means we want to make the removal of a language representative of a family that is present with few languages in the current sample more expensive than the removal of a language from a family that is present in the matrix with many languages.
In addition to the raw coding densities of languages and variables, we want to base our decision as to which of them to prune in a given step on weighted densities. It makes sense to keep languages that are coded for variables of high density and, vice versa, to keep variables coded for languages of high density. Hence, weighted language densities are computed using the variable densities as weights and vice versa. This approach can be iterated.
Identification of Dominant Features in Spatial Data
Roman Flury
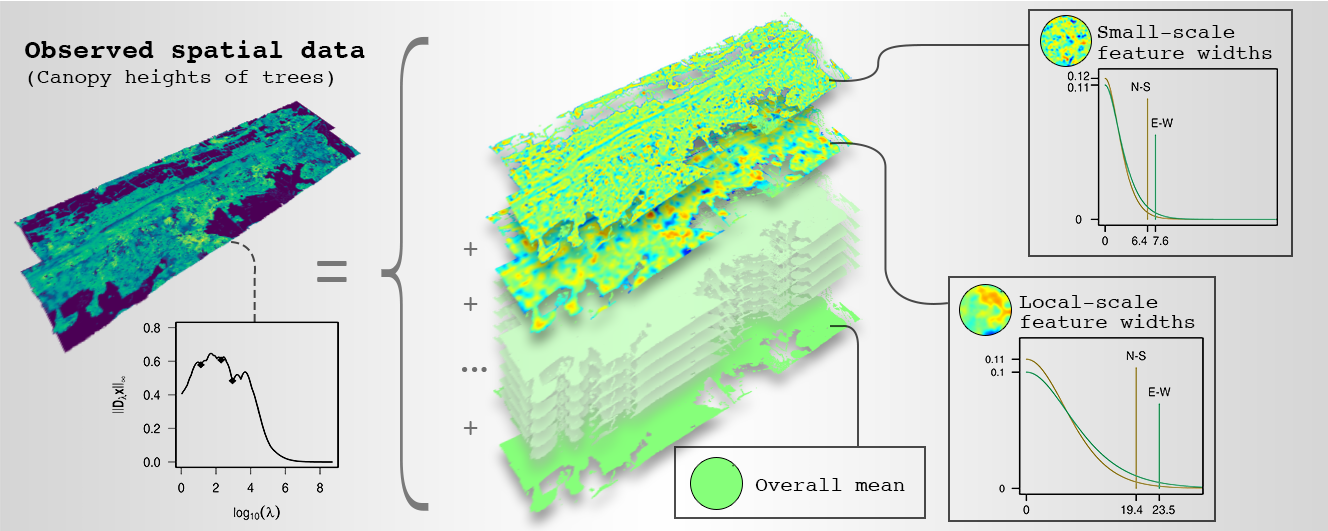
Dominant features of spatial data are connected structures or patterns that emerge from location-based variation and manifest at specific scales or resolutions. To identify dominant features, we propose a sequential application of multiresolution decomposition and variogram function estimation. Multiresolution decomposition separates data into additive components, and in this way, enables the recognition of their dominant features. The data are separated into their components by smoothing on different scales, such that larger scales have longer spatial correlation ranges. Variogram functions are estimated for each component to determine its effective range, assessing the width-extent of the dominant feature. Finally, Bayesian analysis enables the inference of identified dominant features and to judge whether these are credibly different. The efficient implementation of the method relies mainly on a sparse-matrix data structure and algorithms. In disciplines that use spatial data, this method can lead to new insights, as we exemplify by identifying the dominant features in a forest dataset. In that application, the width-extents of the dominant features have an ecological interpretation, namely the species interaction range, and their estimates support the derivation of ecosystem properties such as biodiversity indices.
Publication: https://doi.org/10.1016/j.spasta.2020.100483
Supplementary material https://git.math.uzh.ch/roflur/spatialfeatureidentification.
Spatio-temporally consistent postprocessing of precipitation over complex topography
Stephan Hemri in collaboration with MeteoSwiss
Over the last decade statistical postprocessing has become a standard tool to reduce biases and dispersion errors of probabilistic numerical weather prediction (NWP) ensemble forecasts. Most established postprocessing approaches train a regression type model using raw ensemble statistics as predictors on a typically small set of stations. With high-resolution fields of observed weather data becoming increasingly available, our goal is to assess the potential for spatio-temporally multivariate postprocessing approaches which are able to incorporate the spatio-temporal information from these fields. While having worked mostly with quantile regression based approaches in the beginning, we have moved towards conditional generative adversarial networks (cGAN) in order to be able to generate postprocessed and yet realistic scenarios of forecast precipitation. The figure below shows example forecast scenarios for daily precipitation with a forecast horizon up to five days issued on 1 June 2019 00 UTC. We show the control run of the COSMO-E NWP ensemble along with the corresponding ensemble mean, followed by two forecast scenarios sampled from the cGAN distribution and the pixel-wise mean of 21 cGAN samples. Overall the two cGAN scenarios and the cGAN mean forecast look quite realistic. However, a closer look at the cGAN forecasts still reveals some visual artifacts and also deficiencies in the pixel-wise univariate forecast skill. Currently, we are working on further improving these type of cGAN based postprocessing methods.

Gaussian Process-based Spatially Varying Coefficient Models
Jakob Dambon, in collaboration with Fabio Sigrist (HSLU)
Spatial modelling usually assumes the marginal effects of covariates to be constant and only incorporates a spatial structure on the residuals. However, there exist cases where such an assumption is too strong and we assume non-stationarity for the effects, i.e., coefficients. Spatially varying coefficient (SVC) models account for non-stationarity of the coefficients where their effect sizes are depending on the observation location. We present a new methodology where the coefficients are defined by Gaussian processes (GPs), so called GP-based SVC models. These models are highly flexible yet simple to interpret. We use maximum likelihood estimation (MLE) that has been optimized for large data sets where the number of observations exceeds 105 and the number of SVCs is moderate. Further, a variable selection methodology for GP-based SVC models is presented. A software implementation of the described methods is given in the R package varycoef.

Publications:
- MLE of GP-based SVC Models:
https://doi.org/10.1016/j.spasta.2020.100470 - Variable Selection of GP-based SVC Models:
https://arxiv.org/abs/2101.01932 - R package varycoef:
https://cran.r-project.org/web/packages/varycoef/index.html
(Click on image to enlarge).
Unveiling the tapering approach
Federico Blasi as well as Roman Flury and Michael Hediger
Over the last twenty years, whopping increases in data sizes for multivariate spatial and spatio-temporal data has been recorded and simulated (i.e. remotely sensed data, bathymetric data, weather, and climate simulations, inter alia), introducing a new exciting era of data analysis, yet unveiling computational limitations of the classical statistical procedures. As an example, the maximum likelihood estimation involves solving linear systems based on the covariance matrix, requiring O(n3) operations, which can be a prohibitive task when dealing with very large datasets.
A vast variety of strategies has been introduced to overcome this, (i) through "simpler" models (e.g., low-rank models, composite likelihood methods, predictive process models), and (ii) model approximations (e.g., with Gaussian Markov random fields, compactly supported covariance function). In many cases the literature about practical recommendations is sparse.
In this project, we fill that gap for the tapering approach. Along with a concise review of the subject, we provide an extensive simulated study introducing and contrasting available implementations for the tapering approach and classical implementations, that along with good statistical practices, provides an extensive well-covered summary of the approach.

Software:
- R package spam:
https://cran.r-project.org/web/packages/spam - R package spam64:
https://cran.r-project.org/web/packages/spam64
(Click on image to enlarge).
Detection and Space-Time Modeling of Biome Transition Zones
Leila Schuh in collaboration with Maria Santos and others, URPP Global Change and Biodiversity
Shifting climatic zones result in spatial reconfiguration of potential biome ranges. Particularly ecotones are expected to respond to novel conditions. While temporal trends of individual pixel values have been studied extensively, we analyze dynamics in spatial configuration over time. Landscape heterogeneity is an important variable in biodiversity research, and can refer to between and within habitat characteristics. Tuanmu and Jetz (2015) distinguish between topography based, land cover based, 1st and 2nd-order heterogeneity measures. 1st-order metrics characterize single pixel values, while 2nd-order texture metrics provide information about the spatial relationship between pixels in an area. We utilize and further develop such texture metrics to advance our understanding of landscape heterogeneity as an indicator of large-scale ecosystem transformations.
varrank: a variable selection appoach

Gilles Kratzer
A common challenge encountered when working with high dimensional datasets is that of variable selection. All relevant confounders must be taken into account to allow for unbiased estimation of model parameters, while balancing with the need for parsimony and producing interpretable models. This task is known to be one of the most controversial and difficult tasks in epidemiological analysis.
Variable selection approaches can be categorized into three broad classes: filter-based methods, wrapper-based methods, and embedded methods. They differ in how the methods combine the selection step and the model inference. An appealing filter approach is the minimum redundancy maximum relevance (mRMRe) algorithm. The purpose of this heuristic approach is to select the most relevant variables from a set by penalising according to the amount of redundancy variables share with previously selected variables. In epidemiology, the most frequently used approaches to tackle variable selection based on modeling use goodness-of fit metrics. The paradigm is that important variables for modeling are variables that are causally connected and predictive power is a proxy for causal links. On the other hand, the mRMRe algorithm aims to measure the importance of variables based on a relevance penalized by redundancy measure which makes it appealing for epidemiological modeling.
varrank has a flexible implementation of the mRMRe algorithm which perform variable ranking based on mutual information. The package is particularly suitable for exploring multivariate datasets requiring a holistic analysis. The two main problems that can be addressed by this package are the selection of the most representative variables for modeling a collection of variables of interest, i.e., dimension reduction, and variable ranking with respect to a set of variables of interest.
Publications: https://arxiv.org/abs/1804.07134
Software: https://cran.r-project.org/package=varrank
Spatial fusion modeling
Craig Wang, in collaboration with Milo Puhan, Epidemiology, Biostatistics and Prevention Institute, UZH.
The availability of data has increased dramatically in past years. Multivariate remote sensing data, highly detailed social-economic data are readily to be analyzed to address different research interests. Moreover, the linkage between diverse datasets can be more easily established with the openness trend of database hosts and organizations.
We constructs spatial fusion models within the Bayesian framework to jointly analyze both individual point data and area data. A single source of data may be incomplete or not suitable for parameter inference in statistical models. The cost of data collection especially in large population studies may result useful variables to be omitted, hence limit the scope of research interests. In addition, appropriate statistical models can be complex hence requiring a large amount of data to make precise inference on the weakly identified parameters. Therefore, it becomes crucial in those situations to utilize multiple data sources, in order to reduce bias, widen research possibilities and apply appropriate statistical models.

Time series extension to Additive Bayesian Network
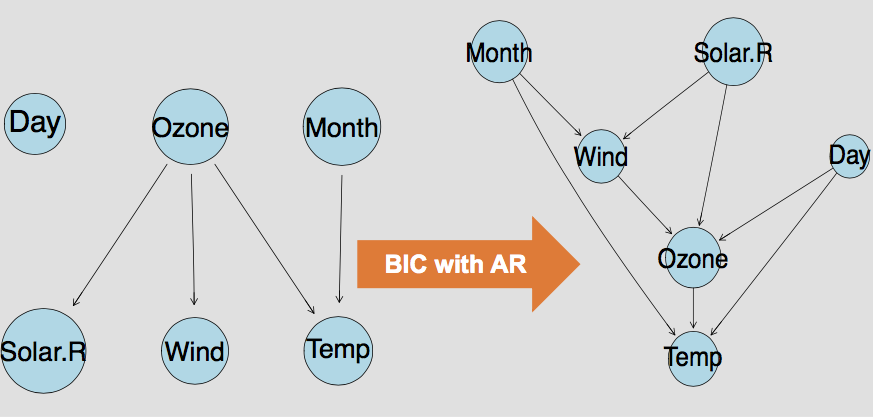
Gilles Kratzer.
In recent years, Additive Bayesian Networks (ABN) analysis has been successfully used in many fields from sociology to veterinary epidemiology. This approach has shown to be very efficient in embracing the correlated multivariate nature of high dimensional datasets and in producing data driven model instead of expert based models. ABN is a multidimensional regression model analogous to generalised linear modelling but with all variables as potential predictors. The final goal is to construct the Bayesian network that best support the data. When applying ABN to time series dataset it is of high importance to cope with the autocorrelation structure of the variance-covariance matrix as the structural learning process relies on the estimation of the relative quality of the model for the given dataset. This is done by using common model selection score such as AIC or BIC. We adapt the ABN framework such that it can handle time series and longitudinal datasets and then generalize the time series regression for a given set of data. We implement an iterative Cochrane-Orcutt procedure in the fitting algorithm to deal with serially correlated errors and cope with the between- and within- cluster effect in regressing centred responses over centred covariate. tsabn is distributed as an R package.
Software: git.math.uzh.ch/reinhard.furrer/tsabn
Landscape Structure: a Mediator Between Food Production and Climate Regulation
Leila Schuh
Modern agricultural production involves large areas of continuous crop fields. Such homogeneous landscapes can contribute to the persistence, if not creation of summer droughts and heat waves. Particularly when harvest occurs during summer, high-pressure conditions are perpetuated. Through interaction with the atmosphere, the land surface influences important climatic variables, such as the sensible and the latent heat flux, the Bowen Ratio and land surface temperature. We investigate the influence of landscape heterogeneity, defined by an increased share of forest patches, on the regional climate. Methodologically, a Soil Vegetation Atmosphere Transfer (SVAT) model is utilized in conjunction with remote sensing data. We found landscape heterogeneity to have a balancing effect on surface temperature and on the partitioning of energy in the year 2003, when a strong heat wave struck Europe. Accordingly, heterogeneous agricultural landscapes provide the means to increase climate regulating ecosystem services.
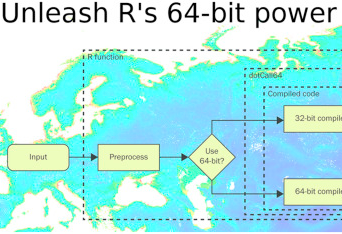
64-bit sparse matrices in R
Florian Gerber
Software packages for spatial data often implement a hybrid approach of interpreted and compiled programming languages. The compiled parts are usually written in C, C++, or Fortran, and are efficient in terms of computational speed and memory usage. Conversely, the interpreted part serves as a convenient user interface and calls the compiled code for computationally demanding operations. The price paid for the user friendliness of the interpreted component is—besides performance—the limited access to low level and optimized code. An example of such a restriction is the 64-bit vector support of the widely used statistical language R. On the R side, users do not need to change existing code and may not even notice the extension. On the other hand, interfacing 64-bit compiled code efficiently is challenging. Since many R packages for spatial data could benefit from 64-bit vectors, we investigated how to simply extend existing R packages using the foreign function interface to seamlessly support 64-bit vectors. This extension is shown with the sparse matrix algebra R package spam. The new capabilities are illustrated with an example of GIMMS NDVI3g data featuring a parametric modeling approach for a non-stationary covariance matrix.
A key part of the 64-bit extension is the R package dotCall64, which provides an enhanced foreign function interface to call compiled code from R. The interface provides functionality to do the required double to 64-bit integer type conversions. In addition, options to control copying of R objects are available.
Developing Bayesian Networks as a tool for Epidemiological Systems Analysis
Gilles Kratzer, in collaboration with the Section of Epidemiology, VetSuisse Faculty, UZH.
The study of the causes and effect of health and disease condition is a cornerstone of the epidemiology. Classical approaches, such as regression techniques have been successfully used to model the impact of health determinants over the whole population. However, recently there is a growing recognition of biological, behavioural factors, at multiple levels that can impact the health condition. These epidemiological data are, by nature, highly complex and correlated. Classical regression framework have shown limited abilities to embrace the correlated multivariate nature of high dimensional epidemiological variables. On the other hand, models driven by expert knowledge often fail to efficiently manage the complexity and correlation of the epidemiological data. Additive Bayesian Networks (ABN) addresses these challenges in producing a data selected set of multivariate models presented using Directed Acyclic Graphs (DAGs). ABN is a machine learning approach to empirically identifying associations in complex and high dimensional datasets. It is actually distributed as an R package available on CRAN.
The very natural extension to abn R package is to implement a frequentist approach using the classical GLM, then to implement classical scores as AIC, BIC etc. This extension could have many side benefits, one can imagine to boost different scores to find the best supported BN, it is easier to deal with data separation in a GLM setting, multilevel of clustering can be tackled with a mixed model setting, there exists highly efficient estimation methods for fitting GLM. More generally, if the main interest relies on the score and not on the shape of the posterior density, then a frequentist approach can be a good alternative. Surprisingly, there exists few available resources to display and analyse epidemiological data in an ABN framework. There is a need for comprehensive approach to display abn outputs. Indeed as the ABN framework is aimed for non-statistician to analyse complex data, one major challenge is to provide simple graphical tools to analyse epidemiological data. Besides that, there is a lack of resource addressing which class of problem can be tackle using ABN method, in terms of sample size, number of variables, expected density of the learned network.
Software:
https://CRAN.R-project.org/package=abn
http://www.r-bayesian-networks.org
Publications:
see also publications of this project
Bayesian hierarchical modeling of anthelmintic resistance

Craig Wang, in collaboration with Paul Torgerson, Section of Epidemiology, VetSuisse Faculty, UZH.
The prevalence of anthelmintic resistance has increased in recent years, as a result of the extensive use of anthelmintic drugs to reduce the infection of parasitic worms in livestock. In order to detect the resistance, the number of parasite eggs in animal faeces is counted. The widely used faecal egg count reduction test (FECRT) was established in the early 1990s. We develop Bayesian hierarchical models to estimate the reduction in faecal egg counts. Our models provide lower estimation bias and provide accurate posterior credible intervals. An R package is available on CRAN, and we have also implemented an user-friendly interface in R Shiny.
Publications:
https://doi.org/10.1016/j.vetpar.2016.12.007
Software:
https://CRAN.R-project.org/package=eggCounts
http://shiny.math.uzh.ch/user/furrer/shinyas/shiny-eggCounts/
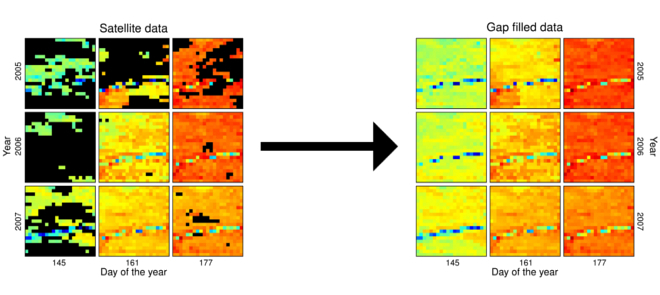
Predicting missing values in spatio-temporal satellite data
Florian Gerber, in collaboration with Rogier de Jong, Michael E. Schaepman, Gabriela Schaepman-Strub
Remotely sensed data are sparse, which means that data have missing values, for instance due to cloud cover. This is problematic for applications and signal processing algorithms that require complete data sets. To address the sparse data issue, we worked on a new gap-fill algorithm. The proposed method predicts each missing value separately based on data points in a spatio-temporal neighborhood around the missing data point. The computational workload can be distributed among several computers, making the method suitable for large datasets. The prediction of the missing values and the estimation of the corresponding prediction uncertainties are based on sorting procedures and quantile regression. The algorithm was applied to MODIS NDVI data from Alaska and tested with realistic cloud cover scenarios featuring up to 50% missing data. Validation against established software showed that the proposed method has a good performance in terms of the root mean squared prediction error. We demonstrate the software performance with a real data example and show how it can be tailored to specific data. Due to the flexible software design, users can control and redesign major parts of the procedure with little effort. This makes it an interesting tool for gap-filling satellite data and for the future development of gap-fill procedures.
Publications:
https://doi.org/10.1109/TGRS.2017.2785240
Software:
https://cran.r-project.org/package=gapfill
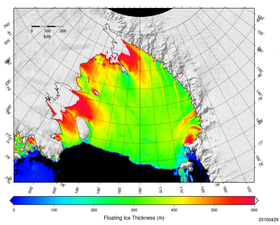
Statistical Ice Shelf Modeling
Towards uncertainty quantification of ice shelves simulations as key components of the global cryosphere
David Masson, in collaboration with Nina Kirchner (Stockholm University)
This project aims at building a nucleus for “Statistical Glaciology” by cross-fertilizing the previously virtually unrelated fields of numerical ice modeling and statistics. While the atmospheric and oceanic modeling community has since long integrated statistical tools in the analysis of uncertainties, the ice sheet modeling community still struggles to provide a systematic quantification of uncertainties of their simulations. Indeed, intricate fluid-dynamics equations often require large amount of computations, which in turn severely limits the estimation of uncertainty by multiple simulation runs.
More specifically, we focus on ice shelves. These 'floating glaciers' are several hundreds of meters thick and play a major role in global climate through their interaction with the polar oceans. Here, the modeling of ice shelves is split into two components : first, a deterministic component provides a gross approximation of the ice-shelf dynamics via a simple 2D-advection of ice into the ocean. The second component consists in stochastic processes that correct the errors made above. The melting processes beneath the ice shelf as well as the shelf's disaggregation in smaller icebergs at the calving front is simulated by statistical models. For instance, ice melting is generated by random Gaussian processes, and ice calving at the shelf's front is modeled by Poisson- and extreme value processes. If this technique can reproduce steady-state ice-shelves in Antarctica, we propose then to simulate several thousands of ice-shelves to explore the parameter space. All simulations leading to steady-states agreeing with present-day observations contains valuable information about plausible parameter ranges. Hence, this study will enable: (i) the quantification of uncertainties in ice shelf simulations, (ii) the identification their driving factors, (iii) and will inform numerical modelers about crucial, yet typically unobservable parameters (e.g. melting rate at the underside of an ice shelf).
Global Change and Biodiversity

Assessing uncertainty in global change–biodiversity research using
multiscale Bayesian modelling
Florian Gerber, in collaboration with Gabriela Schaepman-Strub (IEU, UZH)
We aim to improve the understanding of ecosystem-environment interactions by linking local, sparse field data together with coarse satellite data and data from Earch System Models (ESMs). Spatio-temporal hierarchical Bayesian models will be used to describe the correlation between biodiversity, biophysical feedbacks and climate. Due to the large number of data points and model parameters, estimation is challenging and brute-force Markov chain Monte Carlo (MCMC) simulations are likely to fail. This motivates the developments of suitable approximation techniques. The statistical frame-work will allow us to quantify, e.g., biodiversity–albedo relations and predict their future behavior. Also, uncertainty estimates associated with model parameters and predictions will be derived.
Computer experiments

Evaluation Strategies for Computer Experiments with Medium-sized Datasets
Clément Chevalier, in collaboration with David Ginsbourger (University of Berne)
The design and analysis of computer experiments is a growing topic with important applications in engineering in different domains like nuclear safety, meteorology, finance, telecommunications, oil exploration, vehicle crash-worthiness, etc. In the literature, Gaussian processes are often used as a surrogate model to construct response surfaces of the output of some complex black-box simulator. These models also have the ability to quantify uncertainties and guide parsimonious evaluation strategies of the simulator.
Typical applications, however, are limited to small (typically, less than 1000) number n of observations due to a typical n x n matrix storage and inversion involved in the computations. This research project aims at facilitating the use of computer experiment techniques to dataset of intermediate size (i.e. less than, 50,000 - 100,000), through the use of some well-chosen covariance functions. In particular, we would like to deal with two major issues:
- (Theoretical) Quantify the discrepancy between our covariance models and other typical models.
- (Practical) Adapt some typical sequential evaluation strategies in the computer experiment literature to settings with larger datasets and/or design new strategies.
Climate data analysis
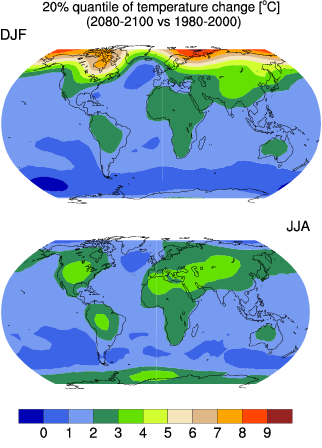
Multivariate Modeling of Large Non-stationary Spatial and Spatio-temporal Climate Fields
Mattia Molinaro, in collaboration with R. Knutti (ETH)
Climate data analysis represents a great challenge not only from a statistical point of view, but also for its implications to other disciplines, such as economics and public health. There are a number of AOGCMs (atmosphere-ocean general circulation models) that are currently being used by scientists to model and possibly predict the extremely complex interactions governing the global climate: it appears therefore crucial to develop a statistical model able to meaningfully combine the obtained results. From this point of view, the project will focus on two main aspects: quantifying the uncertainty resulting from the considered AOGCMs and attributing it to different factors. Accomplishing this task will rely on advanced and tailored techniques, such as finding a proper parametrization of specific GMRFs (Gaussian Markov Random Fields) that model the climate fields related to the aforementioned AOGCMs. In order to take advantage of the available previous knowledge, we choose to develop a hierarchical Bayesian model whose different levels are expected to statistically describe the observations and the prior distributions of the parameters of interest. Via the Bayes theorem, the related posterior distribution can be found. As it happens oftentimes in Bayesian modeling, a closed formula does not exits. As a consequence, it will be necessary to pay particular attention to the computational aspects of the problem: we expect to use both MCMC techniques and Laplace nested approximations via the package INLA. After having developed the above outlined framework, we plan on establishing a multivariate ANOVA model for a specific AOGCM. The aim is to take into consideration the uncertainties inherent future projections and climate change, in order to provide a possible answer to the interdisciplinary questions stated in the introduction.
Bayesian Network
Developing Bayesian Networks as a tool for Epidemiological Systems Analysis
Marta Pittavino, in collaboration with F.I. Lewis and P. Torgerson (VetSuisse).
Bayesian network (BN) analysis is a form of probabilistic modeling which derives empirically from observed data a directed acyclic graph (DAG) describing the dependency structure between random variables.
BN are increasingly finding application in areas such as computational and systems biology, and more recently in epidemiological analysis.

These approaches are relatively new within the discipline of veterinary epidemiology, but promise a quantum leap in our ability to untangle the complexity of disease occurrence because of their capability to formulate and test multivariate model structures. The multivariate approach considers all dependencies between all variables observed in an epidemiological study, without the need to declare one outcome variable as a function of one of more “predictor” variables (the multivariable approach).
Three key challenges exist in dealing with additive Bayesian network and that are going to be tackled within this research project, one theoretical, one epidemiological and another one computational.
Firstly, trying to develop a likelihood equivalent parameter priors for non-conjugate Bns. This will produce a score equivalent metric used to evaluate and discriminate between bayesian network structures.
Secondly, to demonstrate and promote the use of this methodology in epidemiology, relevant and high quality exemplar case studies will be developed showing objectively, situations in which BN models can offer the most added value, relative to existing standard statistical and epidemiological methods.
Thirdly, no appropriate software exists for fitting the types of BN models necessary for analysing epidemiological data, where complexities such as grouped/overdispersed/correlated observations are ubiquitous. This project will develop easy-to-use software to allow ready access to BN modelling to epidemiological practitioners, which is essential in order to make the crucial transition from merely a technically attractive methodology, to an approach which is actually used in practice.
Publications:
PDF of PhD thesis doi:10.5167/uzh-126930
10.1016/j.dib.2017.05.053
10.1016/j.actatropica.2017.04.034
Statistical evaluation of climate model output
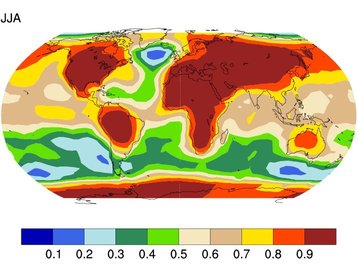
Spatial Hierarchical Bayes Model for AOGCM Climate Projections
Steve Geinitz, in collaboration with R. Knutti, ETHZ, D. Nychka, NCAR, and S. R. Sain, NCAR.
Numerical experiments based on atmospheric-ocean general circulation models (AOGCMs) are one of the primary tools in deriving projections for future climate change. However, each model has its strengths and weaknesses within local and global scales. This motivates climate projections synthesized from results of several AOGCMs' output, combining present day observations, present day and future climate projections in a single hierarchical Bayes model for which the posterior climate change distributions are obtained with computer-intensive MCMC simulations.
We propose to extend the above idea and develop a Bayesian statistical model serving two purposes: quantifying uncertainty and attributing it to different factors. We use spatial statistical models that borrow strength across adjacent spatial regions of the globe in order to provide an statistically accurate assessment of (climate) model bias and inter-model variability. An additional feature of the methodology is the ability to synthesize climate change projections across the different models and then to down-scale to almost arbitrary regions providing a coherent uncertainty estimate.
Development of transmission models for an emergent parasitic zoonosis
In collaboration with P. Torgerson (VetSuisse).
Echinococcus multilocularis, the fox tapeworm, is the cause of human alveolar echinococcosis (AE) a serious and often fatal disease in humans. AE is emergent in Europe and especially Switzerland with increases in the numbers of human cases correlated with the increase in the fox population in Switzerland. This project aims to answer fundamental questions on the transmission biology of this parasite. This host parasite system is also an appropriate model for other parasitic diseases. A modelling approach is appropriate to determine the likely extent of the emerging epidemic of AE, how the system can be destabilised efficiently to ameliorate the epidemic and the risk of the parasite spreading further into non endemic areas. The complex transmission patterns of this parasite will also provide the opportunity to develop new statistical approach for analysis and modelling in host parasite systems. In particular we are interested in the use of spatially explicit models that also account for the uncertainties of diagnosis of the parasite within its hosts.
Towards intelligent continuous compaction control

Multivariate non-stationary spatial mixed-effects models
for roller measurement values
Daniel Heersink, in collaboration with M. Mooney, CSM, R. Anderegg, FHNW.
In this project we attempt to develop complex state-space models for spatial data that are (i) observed indirectly through non-linear measurement operators, (ii) highly non-stationary, (iii) inherently multivariate with dynamic, complex correlation structures, (iv) subject to spatial misalignment and non-linear change-of support characteristics, and are (v) collected in huge quantities.
Such data are, for example, collected by modern earthwork compaction rollers which are equipped with sensors allowing a virtually continuous flow of soil property measurements. The statistical methodology that will be developed in this project can subsequently be used for the design of an intelligent continuous compaction control system.